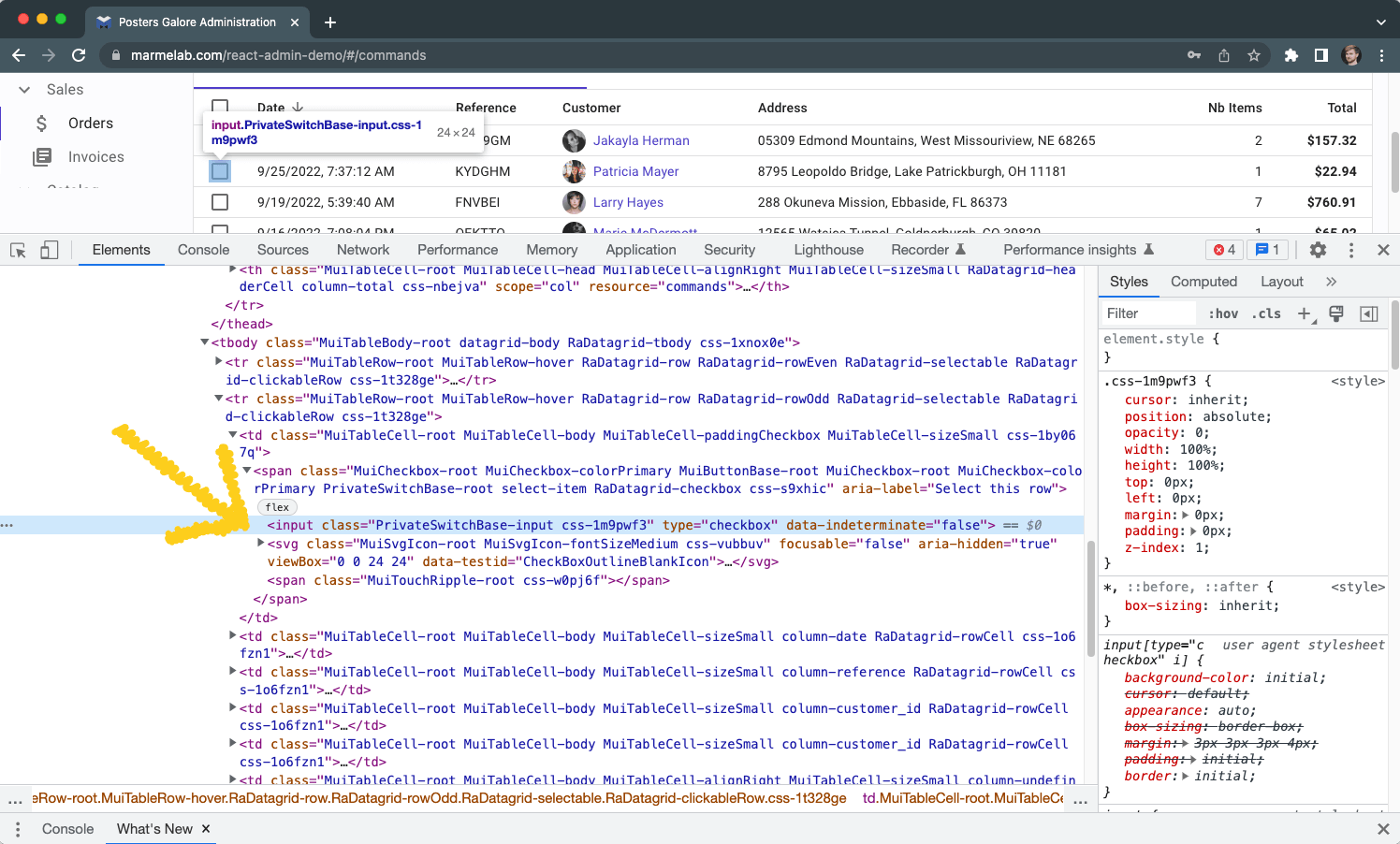
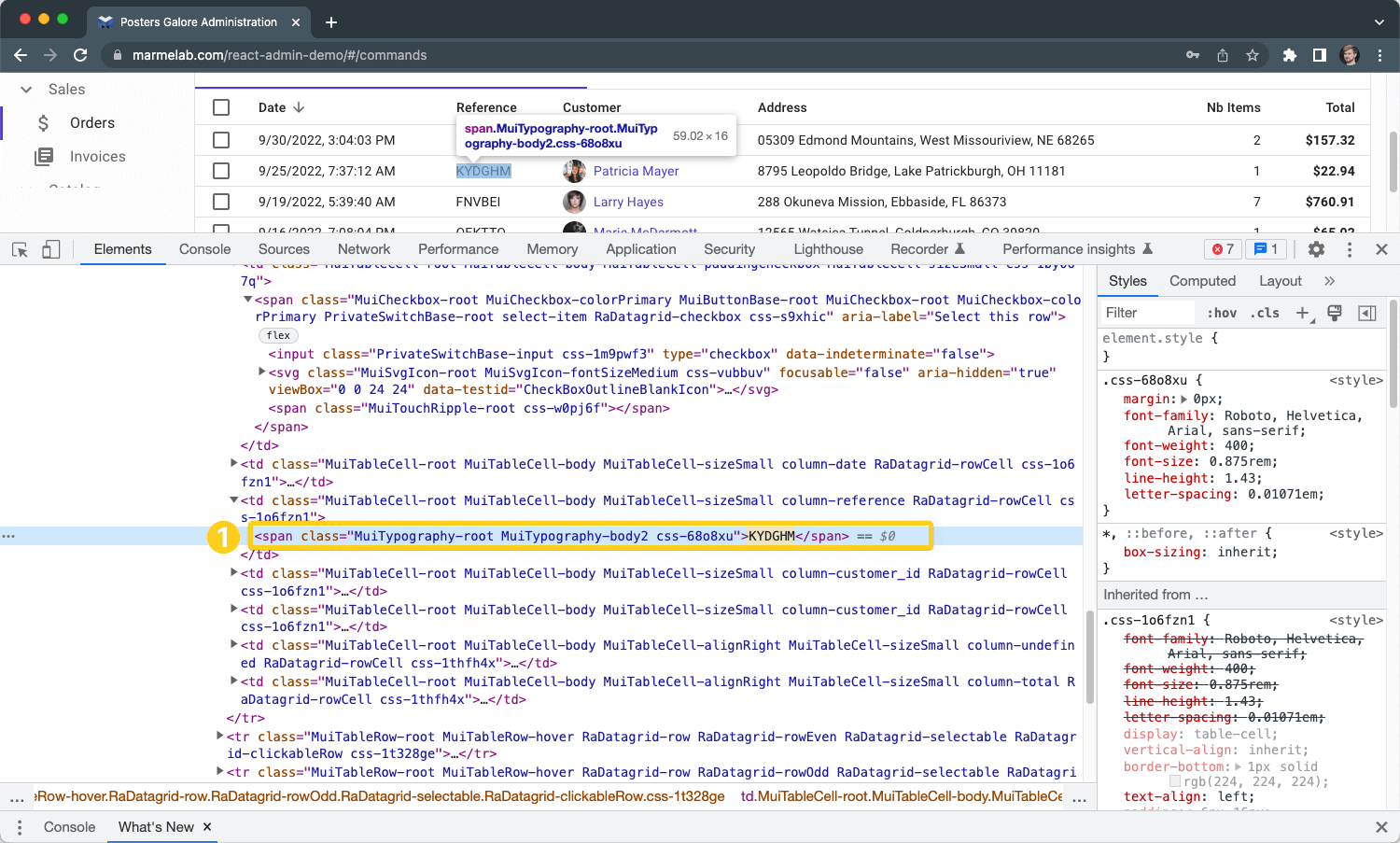
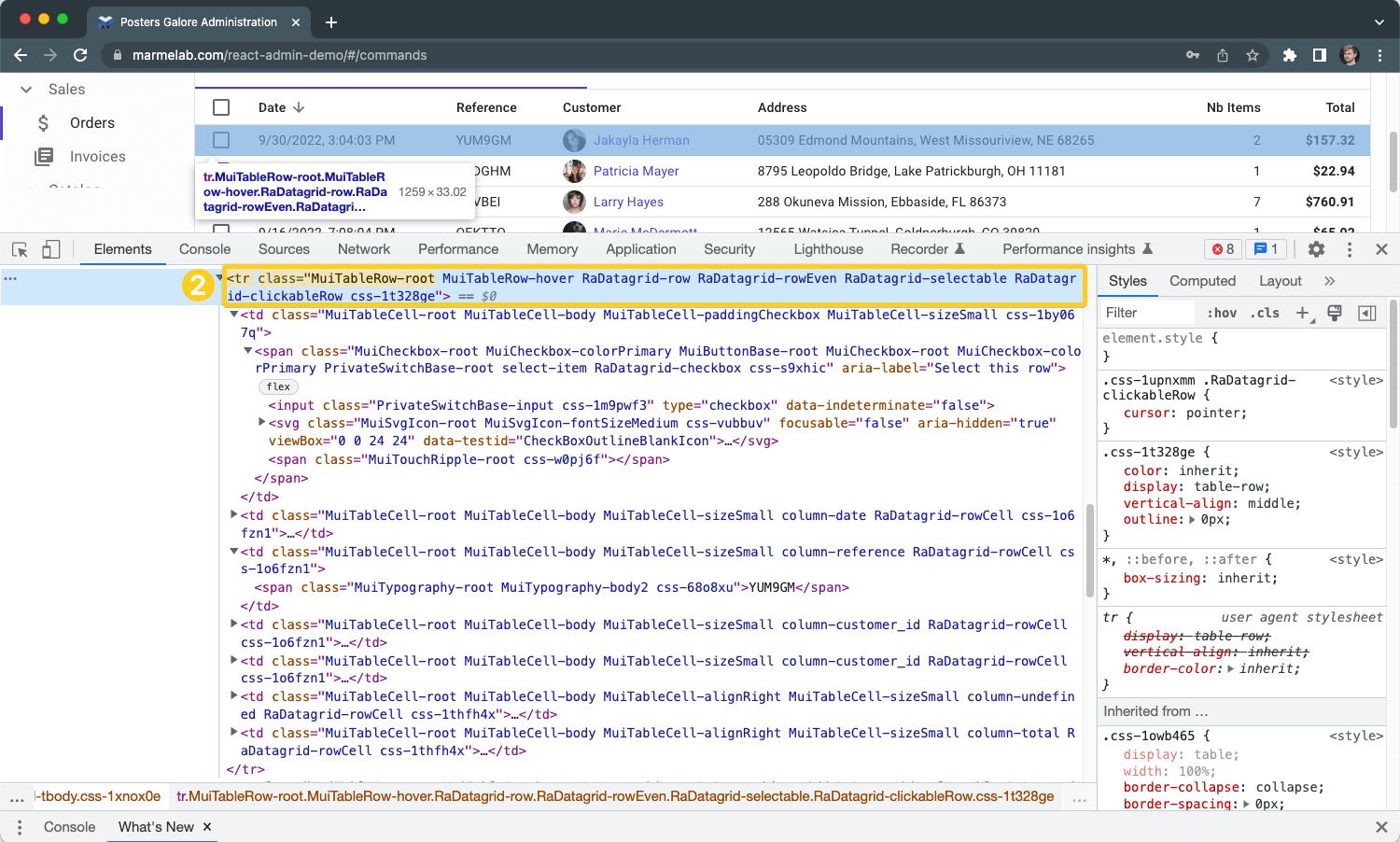
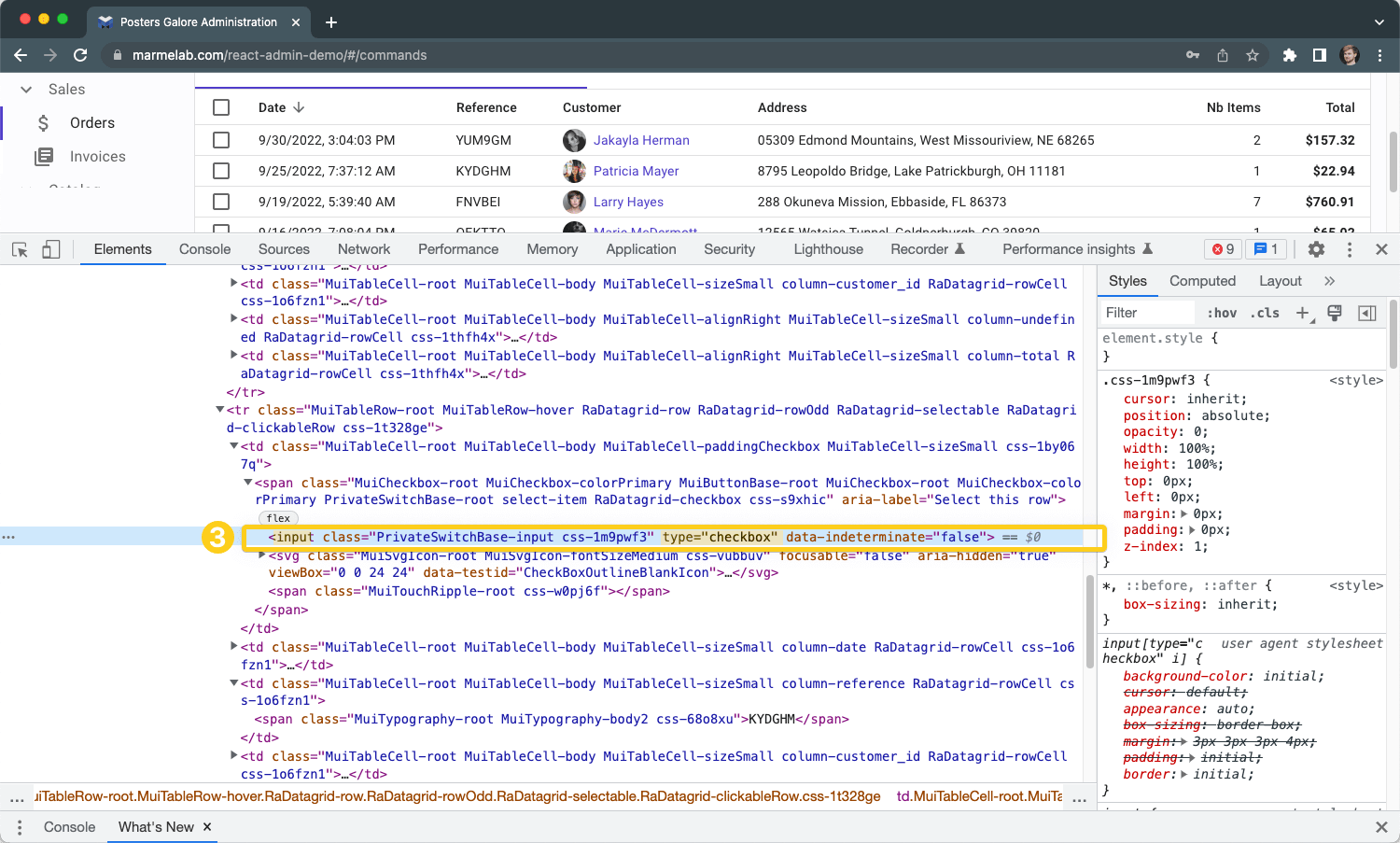
Why use XPath selectors?
If you visited this page, you are probably working on
automation testing. One of the XPath functions is to help in writing automated end-to-end UI
tests. When writing tests you need to specify a test step, for example "Click the submit
button". But computers are not intelligent so they don't know what is a submit button.
You need to specify it. And you need to be very specific, there should be just one button in the
HTML that matches your criteria. Such criteria are called "selectors" or
"locators".
XPath selectors are compex beasts. But very often they are
the only way of creating a reliable automation testing. The XPath technology has been created in
ancient times, when XML databases where popular. It has been developed for querying a database and
complex sets of data, and not for test automation.
🤦 Before we explain how to understand XPath selectors,
let's take a look at some basic of HTML - you need to know the fundamental terminology to
work with selectors.
What is an HTML element
tag?
Tags is the type of HTML element like "div".
Below you can see an example HTML element with its tagged annotated.

Tags often describe the function of the element on your
page.
Some tags are purely descriptive, some add special functionality for the element on page
(like inputs, checkobxes, etc.).
Most common tags are:
div, span, footer, nav - usually static
elements, no special function
td, th, tr - tags for HTML
tables
href - for links
li, ol, ul - bullets list or numbered lists
input, textarea, select- for text input fields, radio buttons, checkboxes
form, label, name- tags used inside HTML forms, sometimes have special functions
(for example clicking the label also ticks the checkbox)
img,
video, svg- for media files,
videos, images
What is an HTML attribute?
An attribute is an additional parameter in the HTML code
that is not visible to the end-user.

Here are some common attributes and our tips if they are a
good selector:
class - typically used for styling with CSS,
many items can have the same class
id - unique attribute for
specific element, in theory there should be no two elements with the same id (but that's not
always true)
src - usually for some media source, like image
file
aria-label - used for accessibility and screen-readers,
but also can make quite good selectors for test automation
data-testid - special selector that is dedicated to test automation,
needs to be implemented by a developer
There are hundreds more!
What are parents,
children & siblings?
HTML documents have a hierarchical structure. It's
similar folders and files. Elements can be nested inside other elements on your web page. If an
element is inside another, it's called a child. The upper-level element is a
parent. Elements on the same level are called siblings.
Another terminology
is ancestors or descendants - see the image below

How to read XPath
selectors?
Here's an example of the simplest XPath
selector.
//div
It means: Find any "div"
element.
This selector is not very specific as it will find hundreds of elements on your
page.
You can add additional filters to your selectors in square brackets.
//div[3]
It means: Find element with tag "div" that
is third
This selector is based on order of elements and is not a good selector for test
automation. If your app changes, for example, developers add another div in the HTML structure,
such selectors will stop working.
You can add filters to your selectors that are based on
other HTML attributes.
//div[@id="submit-button"]
It means: Find any
element with tag "div" that has an attribute "id" with value
"submit-button.
You can have more than one filters if you add more square
brackets. You can also filter elements by text content.
//div[@id="submit-button"][contains(text(), "Sign
in")]
It means: Find any element with tag "div" that
has an attribute "id" with value "submit-button"
and contains text "Sign in"
If you see a
slash / in the middle of the selector, it means that this
selector is a combination of several smaller selectors, each of them can have its own
filters.
//div[@id="submit-button"][contains(text(), "Sign
in")]/div[@id="arrow"]
It means: Find any element with
tag "div" that has an attribute "id" with value "submit-button
and contains text "Sign in",
then inside this element
find another div that has attribute "id" with value "arrow".
The
above example first looks for an element matching this selector //div[@id="submit-button"][contains(text(), "Sign
in")]
and then looks for another element inside the previously found
element with selector /div[@id="arrow"]
By default,
after a / character, XPath is looking inside the element, but
you can add special operators that allow you to traverse to parent elements or siblings. The
operators are for example ancestor:: , descendant:: or ::sibling
//div[@id="submit-button"][contains(text(), "Sign
in")]/sibling::div[@id="arrow"]
It means: Find any
element with tag "div" that has an attribute "id" with value
"submit-button and contains text "Sign in",
then find sibling of this
element that has attribute "id" with value "arrow".
Read more
below to learn what are parents, children, ancestors, descendants, siblings, etc.